见图片,Skip-Gram模型是Word2Vec模型的一种,属于词嵌入模型,故AD错误。C选项说的是Word2Vec模型的另一种CBOW模型。
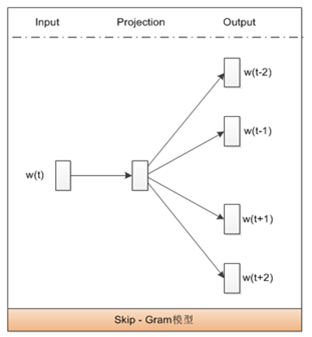
正确答案是:B: 模型的目标是最大化用当前的词预测上下文的词的生成概率。
专业分析:
Skip-Gram模型是一种用于训练词向量的神经网络模型,它的主要目标是通过给定的中心词来预测其上下文中的词语。因此,Skip-Gram模型的目标是最大化用当前的词预测上下文的词的生成概率,这与选项B描述的内容一致。
具体来说,Skip-Gram模型通过以下步骤实现其目标:
1. 给定一个中心词,模型会在一定范围内选择上下文词。
2. 使用神经网络来训练模型,使得中心词的词向量能够有效地预测这些上下文词的词向量。
3. 通过最大化预测正确上下文词的概率,模型不断调整词向量,使得相似的词在向量空间中距离较近。
选项A和D提到的词袋模型和词集模型并不是Skip-Gram模型的特征。词袋模型(Bag-of-Words, BoW)是一种简单的文本表示方法,不考虑词序,而词集模型并不是一个常见的术语。
选项C提到的通过上下文的词预测当前词生成概率,描述的是另一种常见的词向量训练方法——CBOW(Continuous Bag of Words)模型,而不是Skip-Gram模型。
