新用户注册
备考刷题,请到
CDA认证小程序
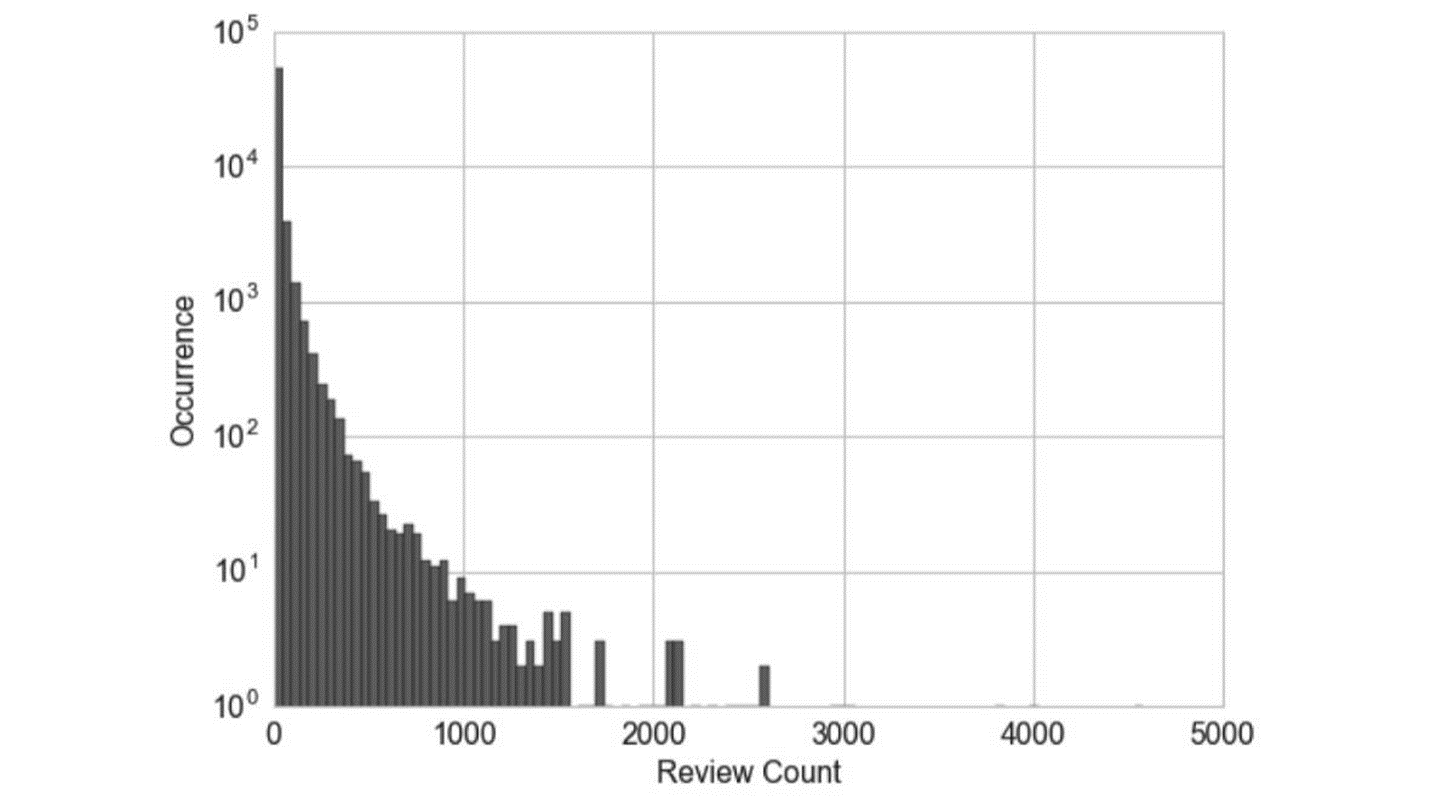
答案是:A: 数据过于集中在较小的部分。 专业分析: 从图中可以看出,点评数量的数据分布呈现出一种长尾分布的特征,即大多数商家的点评数量集中在较小的区间,而少数商家的点评数量非常大。这种分布特点在很多实际数据中是常见的,尤其是在用户行为数据中。 离散化的原因主要包括以下几点: 1. **数据过于集中在较小的部分**:如图所示,大多数商家的点评数量集中在较小的区间。如果直接使用原始数据进行建模,模型可能会受到这些高频小值的影响,导致预测结果不准确。通过离散化,可以将这些数据分成若干个区间,使得每个区间的数据量更加均匀,有助于提高模型的稳定性和预测能力。 2. **处理长尾分布**:长尾分布的数据在进行建模时,容易受到极端值的影响。通过离散化,可以减少这些极端值对模型的影响,使得模型能够更好地捕捉数据的整体趋势。 3. **简化模型复杂度**:离散化可以将连续变量转换为分类变量,简化数据的复杂度,便于后续的特征工程和模型训练。 4. **提高模型的鲁棒性**:离散化后的数据对异常值和噪声的敏感度较低,有助于提高模型的鲁棒性和泛化能力。 综上所述,数据过于集中在较小的部分是进行离散化的主要原因,这样可以更好地处理数据的长尾分布,减少极端值的影响,提高模型的预测性能。