Skip-gram考虑的主要思想是要P( Context(w) | w )的概率最大化,所以接下来看Skip-gram模型主要就是看如何定义和计算这个概率。(当然对于语言模型来说,实际的目标函数通常是对语料库中的每个词的概率P( Context(w) | w )取对数再累加)
输入层:词w的向量
投影层:依旧是词w的向量
输出层:哈夫曼树(重点是词w的上下文窗内2c个词所在的叶子节点,以及各自到根节点的路径)
结论:Skip-gram模型的一次更新是:输入中心词w的词向量,然后对每个上下文词u(i)所在的路径上的节点系数进行更新,然后对词w的词向量进行单独更新。
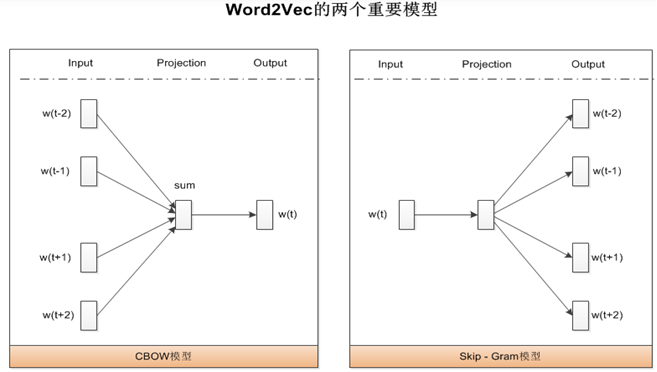
在word2vec中,CBOW(Continuous Bag of Words)和Skip-Gram是两种常用的模型,用于将文本中的词汇转化为向量表示。以下是对这两种模型的详细描述和分析:
1. **CBOW模型**:
- **输入**:周围词的词向量。
- **输出**:当前词的词向量。
- **描述**:CBOW模型通过利用上下文中的多个词来预测当前词。换句话说,给定一个词的上下文(即前后若干个词),CBOW模型试图预测这个中心词。
2. **Skip-Gram模型**:
- **输入**:当前词的词向量。
- **输出**:周围词的词向量。
- **描述**:Skip-Gram模型通过利用当前词来预测其上下文中的多个词。也就是说,给定一个中心词,Skip-Gram模型试图预测这个词的前后若干个词。
根据上述描述,正确答案是:
- **A: Skip-Gram模型输入的是当前词的词向量**(正确)
- **D: CBOW模型输出的是周围词的词向量**(正确)
因此,正确的选项为A和D。
