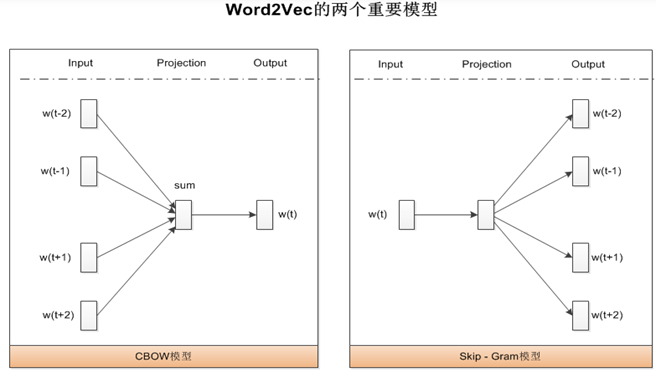
CBOW考虑的主要思想是要P( w | Context(w) )的概率最大化,所以接下来看CBOW模型主要就是看如何定义和计算这个概率。(当然对于语言模型来说,实际的目标函数通常是对语料库中的每个词的概率P( w | Context(w) )取对数再累加)
输入层:词w前后c个,共2c个词的词向量
投影层(隐藏层):对这2c个词向量求和. 因为CBOW使用的是词袋模型,因此这2c个词都是平等的,也就是不考虑他们和我们关注的词之间的距离大小,只要在我们上下文之内即可。
输出层:以语料库出现的词为叶子节点,以词在语料库中出现的次数为权重,构造Huffman树。这颗Huffman树的叶子节点共有D个(语料库中词的个数), 非叶子节点共有(D-1)个。
结论:CBOW模型的一次更新是:输入2c个词向量的累加,然后对中心词w上的路径节点系数进行更新,然后对所有的上下文词的词向量进行整体一致更新。
正确答案是:B: 池化层
专业分析:
CBOW(Continuous Bag of Words)模型是一种用于自然语言处理的词嵌入模型。它的主要目的是通过上下文词来预测中心词。CBOW模型的结构相对简单,通常包括以下几个部分:
1. **输入层**:输入层接收上下文词的词向量表示。
2. **隐藏层**:隐藏层将输入的词向量进行线性变换和求平均,以得到一个固定长度的向量表示。
3. **输出层**:输出层通过一个softmax函数来预测中心词的概率分布。
池化层(Pooling Layer)通常用于卷积神经网络(CNN)中,以减小输出维度和计算量,但在CBOW模型中并不包含池化层。因此,B: 池化层 是不包含在CBOW模型中的。
总结:CBOW模型的主要组件包括输入层、隐藏层和输出层,但不包含池化层。
