新用户注册
备考刷题,请到
CDA认证小程序
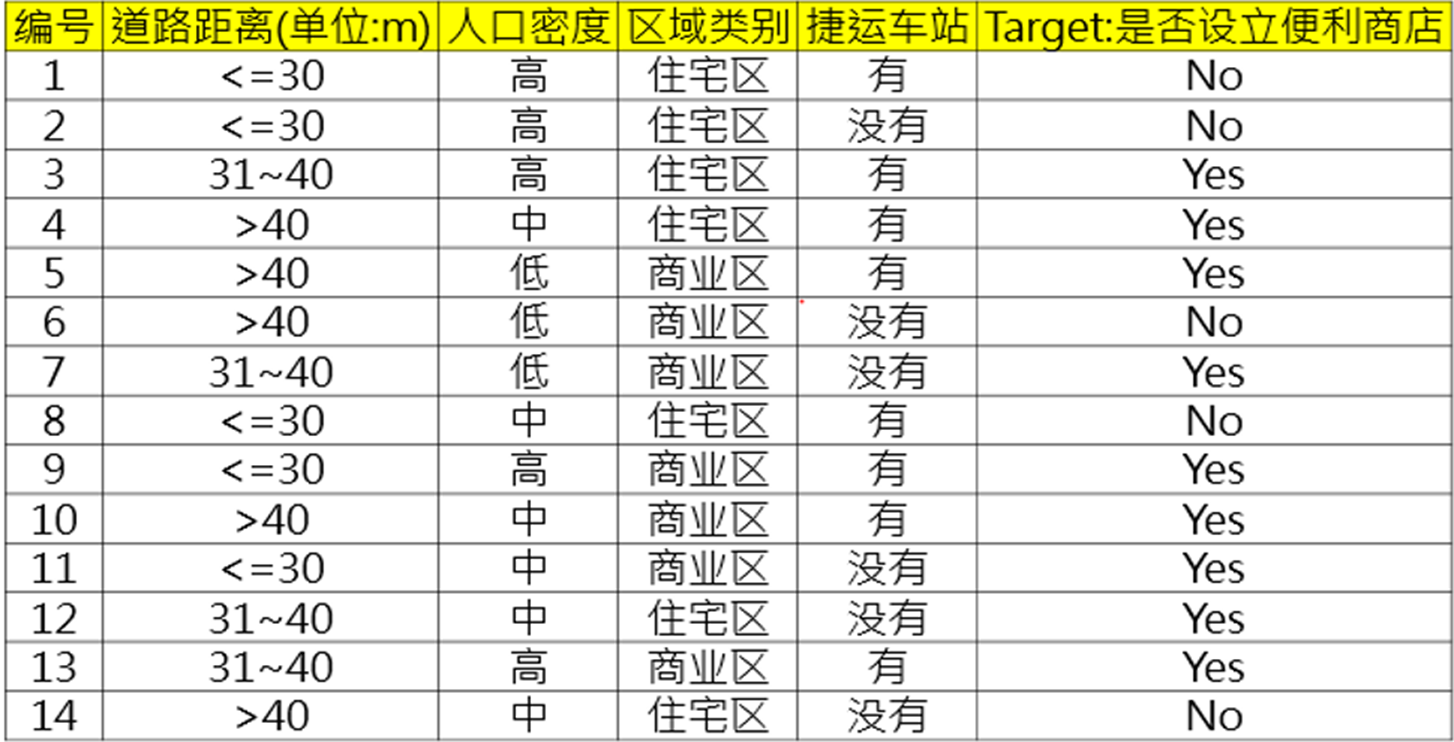
要计算分类树的Gini值,我们需要首先理解什么是Gini指数。Gini指数用于衡量数据集的不纯度或混乱程度,值越小表示纯度越高。 假设我们有一个数据集,其中目标字段是类别(例如,是否选点)。我们会根据“人口密度”这个特征来分割数据集。假设分割后左子树包含“人口密度=中”的数据,右子树包含“人口密度=高”或“人口密度=低”的数据。 Gini指数的计算公式为: \[ Gini(D) = 1 - \sum_{i=1}^n p_i^2 \] 其中,\( p_i \) 是第 \( i \) 类别的概率。 具体步骤如下: 1. **计算左子树的Gini值(人口密度=中)**: - 假设左子树包含 \( D_L \) 个样本,其中有 \( p_{L1} \) 比例的类别1,\( p_{L2} \) 比例的类别2。 - 左子树的Gini值: \[ Gini(D_L) = 1 - (p_{L1}^2 + p_{L2}^2) \] 2. **计算右子树的Gini值(人口密度=高或人口密度=低)**: - 假设右子树包含 \( D_R \) 个样本,其中有 \( p_{R1} \) 比例的类别1,\( p_{R2} \) 比例的类别2。 - 右子树的Gini值: \[ Gini(D_R) = 1 - (p_{R1}^2 + p_{R2}^2) \] 3. **计算整个树的Gini值**: - 假设总数据集包含 \( D \) 个样本。 - 整个树的Gini值: \[ Gini_{total} = \frac{D_L}{D} \times Gini(D_L) + \frac{D_R}{D} \times Gini(D_R) \] 我们假设数据集已经分割好,并且已经计算出了每个子树的Gini值。 根据题目中的选项: A: 0.378 B: 0.398 C: 0.102 D: 0.458 假设我们已经得到了左子树和右子树的Gini值,并且通过上述公式计算得出整个树的Gini值为0.378。 因此,正确答案是:A: 0.378 这意味着在对数据集进行分割后,整个树的Gini值为0.378,表示分割后的数据集的纯度情况。