 2026-04-29
2026-04-29
本勘误表旨在修正《CDA二级教材(第4版)》印刷中出现的各类错误,建议读者在阅读教材时,对照本表对相关内容进行标注和更正。后续若发现新的错误,我们将及时更新勘误表并发布。
| 序号 | 勘误位置 | 原内容 | 修正内容 |
|---|---|---|---|
| 1 | P3,p4 |  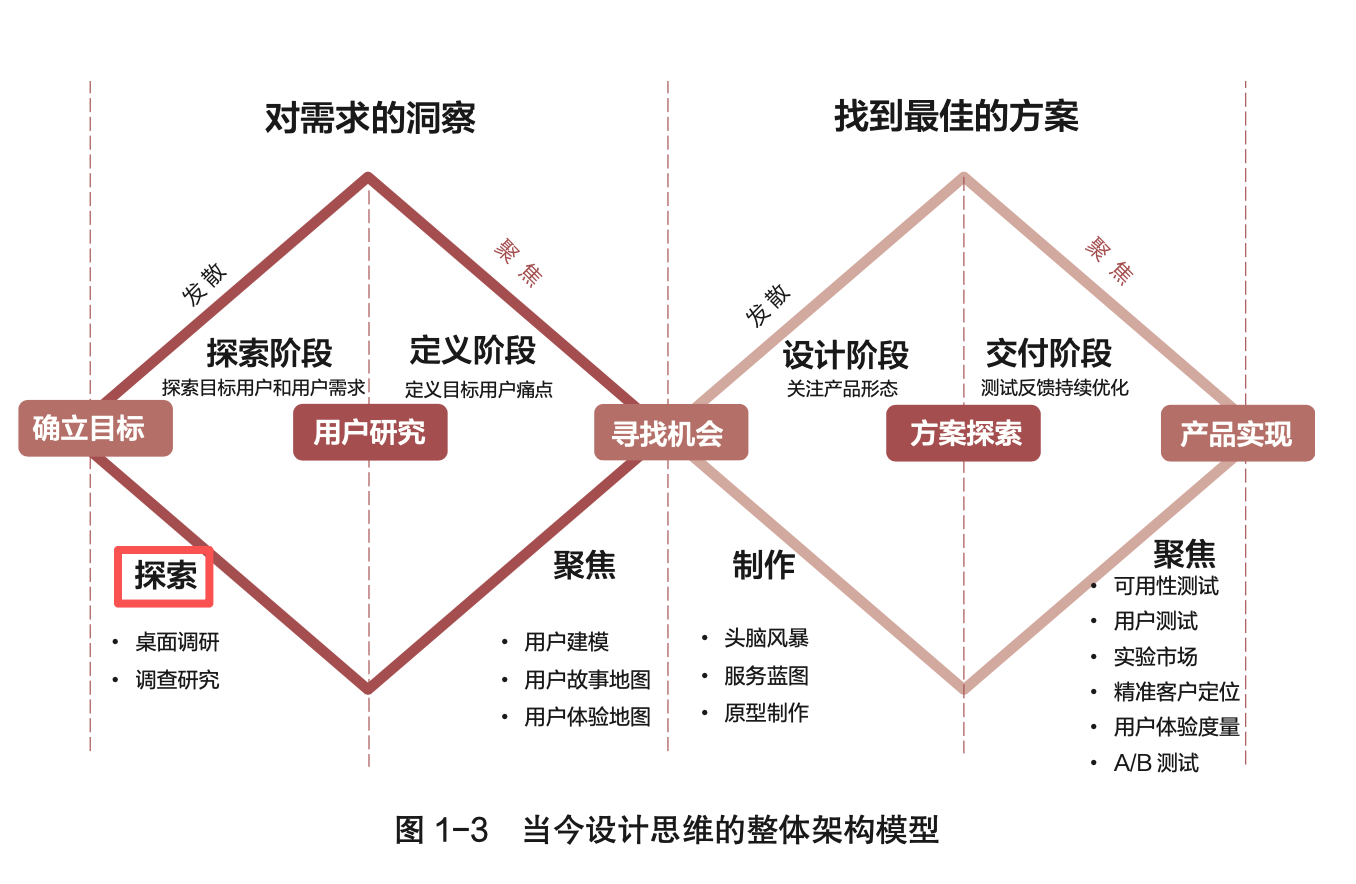 |
"P3,“探索(Discover)阶段”改成“探查(Discover)阶段”; "P4,图1-3,左下角,“探索”改成“探查 |
| 2 | P9 |  |
"(4)"修改为“(3)" |
| 3 | P53 |  |
表达式修改为"DF[DF.col.str.contains(‘^M’)]" |
| 4 | P57 |  |
"100"修改为"1000" |
| 5 | P113 | 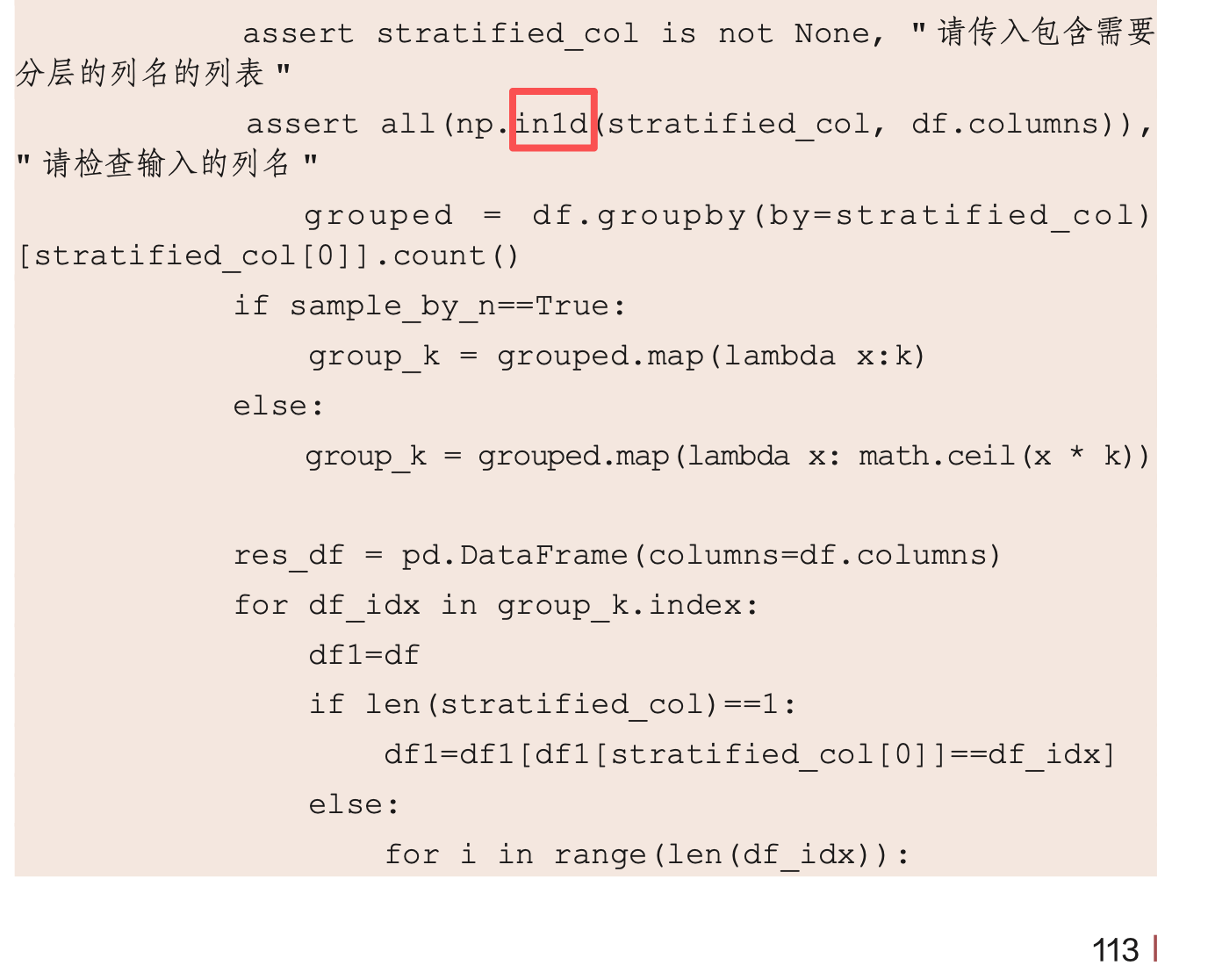 |
"in1d"修改为"isin" |
| 6 | P129 | 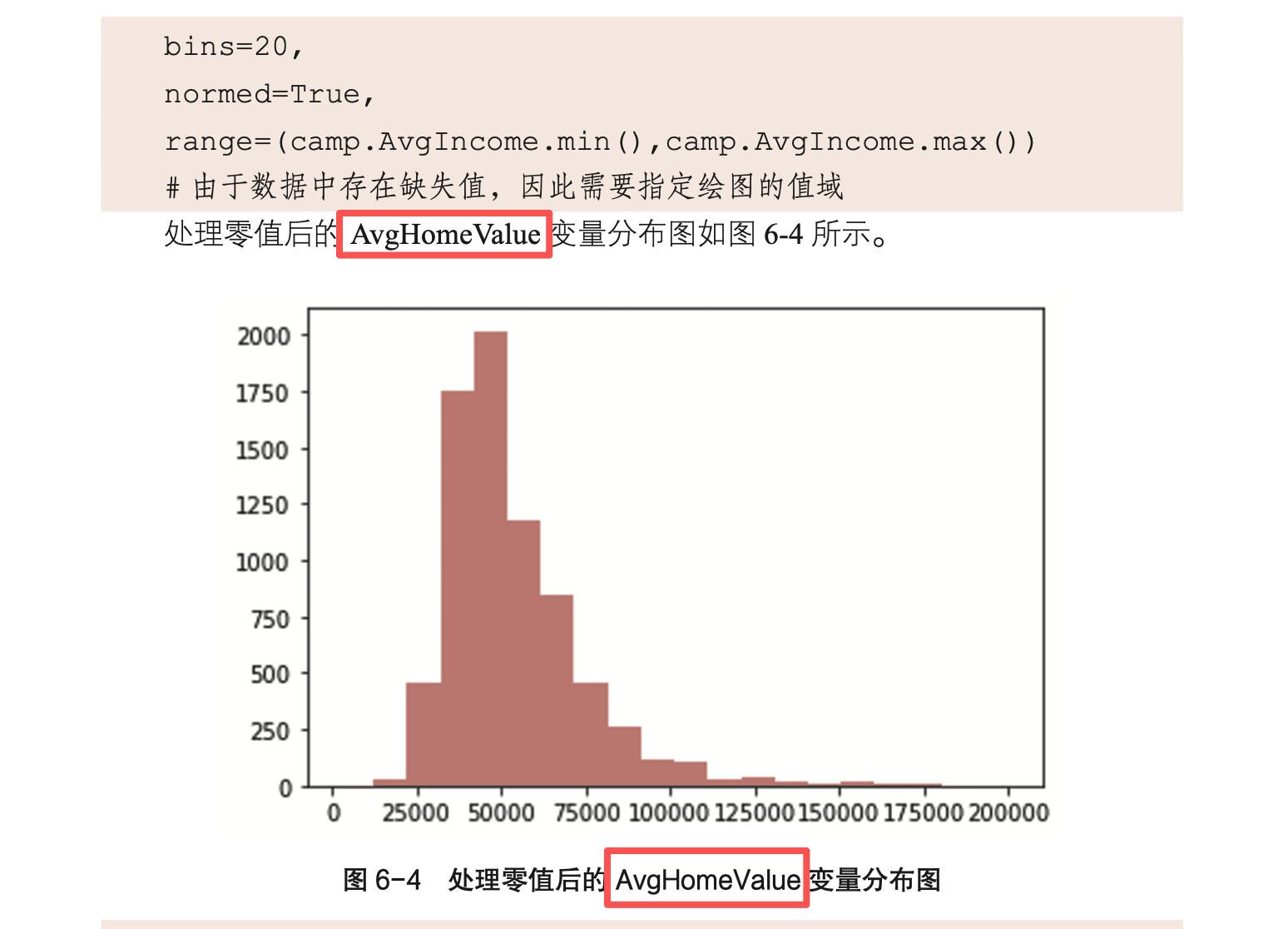 |
修改为“AvgIncome” |
| 7 | P137 |  |
修改为“第一种是百分位秩。百分位秩就是把变量从小到大排列,然后依次赋予序列号,最后用序列号除以总的样本量再乘以100,值域为 [0,100]。” |
| 8 | P179,P180 |  |
修改为“函数dropna前加“.”” |
| 9 | P185 |  |
将代码修改为“print("chisq=%6.4f\np-value=%6.4f\ndof=%d\nexpected_freq=%s” %stats.chi2_contingency(cross_taable.iloc[:2,:2]),输出为:chisq=2.7098,p-value=0.0997 dof=1 expected_freq=[[4149.15422886 1030.84577114] [358.84577114 89.15422886]]] 卡方值为:2.7098,P值为0.0997 |
| 10 | P221 |  |
文字修改为:可以看到,使用summary可以查看模型的一些信息。包括第一部分模型基本信息,Converged显示为False,这里意味着模型没有收敛,可能的原因有:多重共线性、样本量不足或变量过多、迭代次数不足等。第二部分是模型的参数估计及检验,从检验结果来看(假设Converged为True),连续型变量incomeCode和nrProm是不显著的。对于不显著变量是删除还是保留,仍然要结合对业务的理解。所以说,业务专家在一个商业数据挖掘项目当中是很有必要的。分类变量curPlan和avgplan标准误极大,P值为0这说明这些分类变量中的某些类别可能只有极少数的样本,或者完全对应某一种结果。对于上述这种情况先尝试删除这两个变量的其中一个,比如删除avgplan。然后检查保留下来的另一个变量(curPlan)各类别的分布情况,确保没有某个类别近似都是常数。然后重跑一次逻辑回归。 |
| 11 | P228 |  |
特异度(Specificity/True Negative Rate) |
| 12 | P229 | 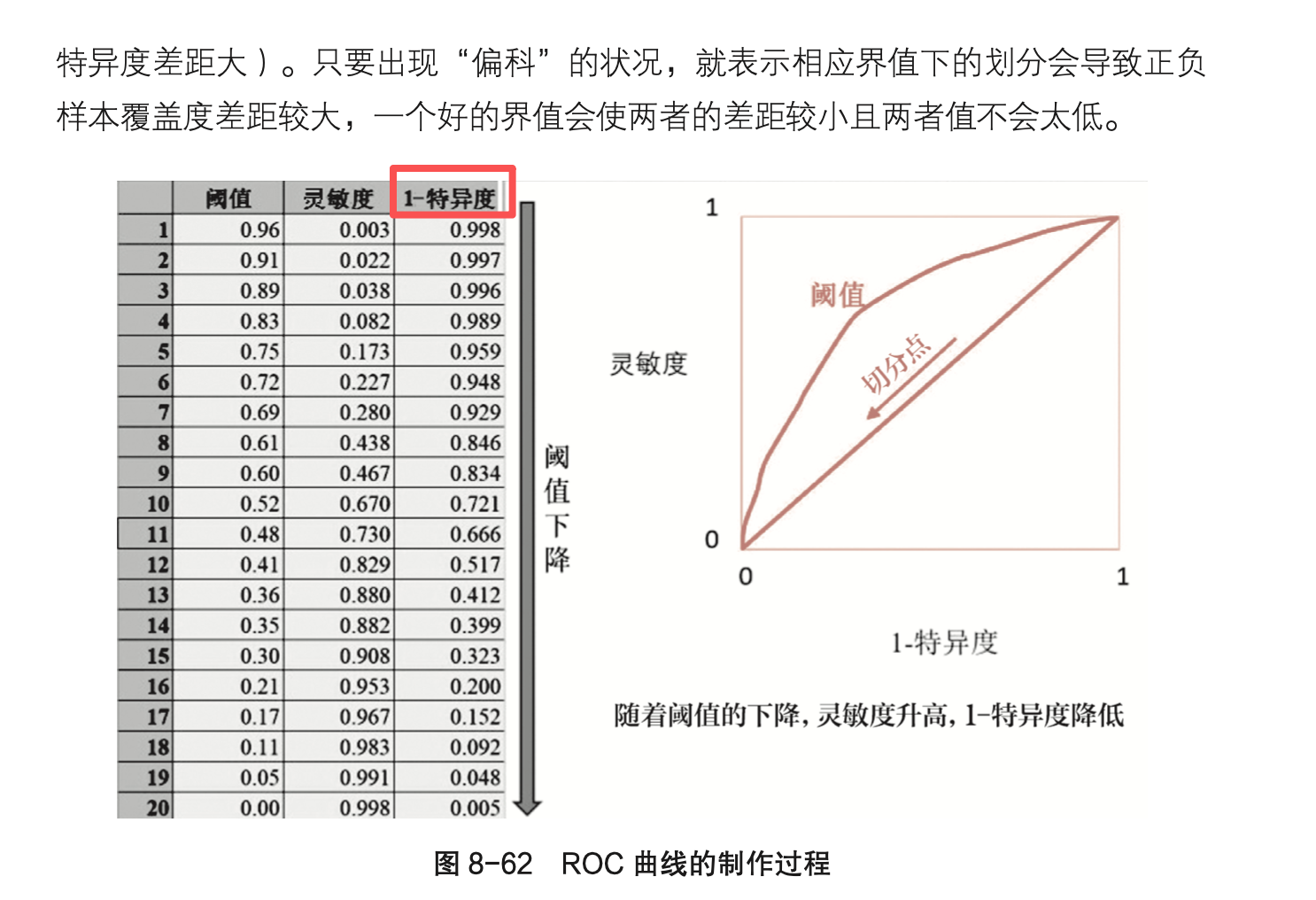 |
特异度 |
| 13 | P243 | 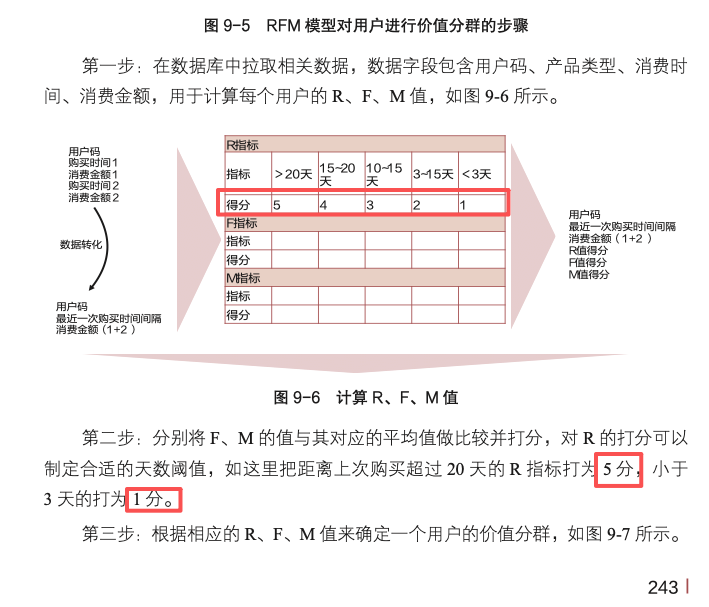 |
分别修改为:得分改为1、2、3、4、5;20天的R指标打为1分,小于3天的打5分 。 |
| 14 | P250 |  |
越大,表明群之间差异越大,聚类效果越好。 |
| 15 | P256 |  |
data = preprocessing.scale(data) 修改为“data = preprocessing.scale(model_data) ”。 |
| 16 | P257,P264 |  |
“获取因子得分”修改为“获取因子权重”。 |
| 17 | P258 |  |
“scaler_model_data”修改为“data”。 |
| 18 | P259 |  |
“dismat=sch.distance.pdist(citi10_fa[["Gross","Avg"]],metric='euclidean')”修改为“dismat=sch.distance.pdist(fa_scores[["Gross","Avg"]],metric='euclidean')”。 |
| 19 | P269 |  |
改为:决策树可以分为基于熵增益的ID3决策树和基于熵增益率的C4.5决策树 |
若您在使用教材过程中,发现了其他错误或有任何疑问,欢迎通过以下方式与我们联系:
发送电子邮件至:exam@cdaglobal.com,邮件主题请务必注明‘《CDA二级教材(第4版)》错误反馈’,并在邮件正文中详细描述错误位置、原内容及您认为正确的内容。
完 谢谢观看
上一篇: 《CDA一级教材》勘误表(第 4 版)
CDA认证
关于CDA考试 最新考试安排 考试报名入口 CDA证书查询CDA合作
CDA教育 Pearson CDA网校 电子工业出版社关注CDA
关于我们 Email:exam@cdaglobal.com 电 话:010-68454276 手 机:15311595173 CDA认证小程序
CDA认证小程序
 CDA考试中心服务号
CDA考试中心服务号
 京公网安备 11010802034615号
京公网安备 11010802034615号
