ROC和AUC是分类模型常用的评价指标,K-S值用于对模型风险区分能力进行评估,指标为好坏样本累计部分的插值,一般 K-S曲线的最大值代表K-S统计量,ks指标越大,模型风险区分能力越强。
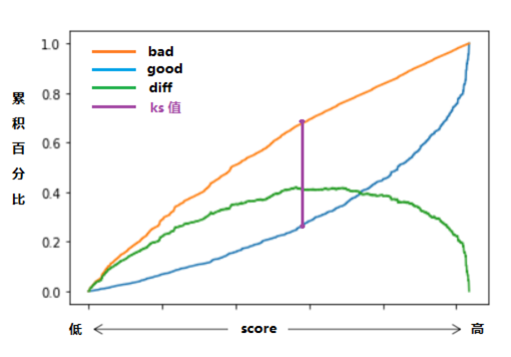
纵轴为好坏客户的累计百分比(累计TPR、累计FPR),横轴为评分从低到高排序 后的各值,或者对应的样本占比。
其中,TPR(真正率/召回率:实际为坏客户中预测为坏客户的比 例)TPR=TP/(TP+FN) FPR(假正率:实际中为好客户预测为坏客户的比例)FPR=FP/(FP+TN),值,为评分卡的K-S值。
Gini系数和AUC本质相同,它和AUC存在这样的线性关系,
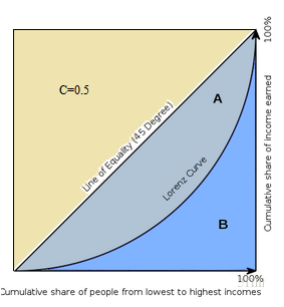
上图是Gini曲线,和AUC曲线的横纵坐标正好相反,其定义为Gini系数 = A / (A + B) 。由于Gini曲线,和AUC曲线的横纵坐标正好相反,易知AUC=A+C。
常用的区分好坏客户的指标有以下几种:
A: AUC (Area Under the Curve)
B: ROC (Receiver Operating Characteristic)
C: KS (Kolmogorov-Smirnov)
D: Gini系数
正确答案是:A: AUC, B: ROC, C: KS, D: Gini系数
专业分析如下:
1. **AUC (Area Under the Curve)**: AUC 是 ROC 曲线下的面积,表示模型区分好坏客户的能力。AUC 值越接近 1,模型的区分能力越强,AUC 值为 0.5 表示模型没有区分能力,相当于随机猜测。
2. **ROC (Receiver Operating Characteristic)**: ROC 曲线展示了不同阈值下模型的真阳性率(TPR)和假阳性率(FPR)之间的权衡。通过观察 ROC 曲线,可以直观地了解模型的性能。
3. **KS (Kolmogorov-Smirnov)**: KS 统计量是累计分布函数(CDF)之间的最大差异。具体来说,是好客户和坏客户的累计分布函数之间的最大差异。KS 值越大,模型区分好坏客户的能力越强。
4. **Gini系数**: Gini 系数是通过对 Lorenz 曲线进行计算得到的,表示模型的不平等程度。Gini 系数与 AUC 有直接关系,Gini 系数 = 2 * AUC - 1。Gini 系数越高,模型的区分能力越强。
这些指标都是评价信用评分模型性能的重要工具,通过这些指标,可以更好地理解和优化模型的预测能力。
